CNN(Convolution Neural Network)은 근래에 시각 인식 인공지능에 자주 사용되는 네트워크 구조입니다. CNN이 자주 사용되는 이유는 무엇보다도 다른 것들보다 좋은 성능을 보이기 때문입니다. 이 글은 CS231n 유튜브 강의 9강에서 다룬 Imagenet classification 대회에서 좋은 성적을 거둔 CNN Architecture에 대해 소개할 것입니다.
0. History of Imagenet Classification Winners

각 년도에 해당하는 Imagenet Classifcication 승자의 error rate는 위와 같습니다. 여기서 저희는 AlexNet, GoogLeNet, ResNet, VGG Net에 대해 알아보겠습니다. (2013년에 1위를 차지한 ZFNet은 12년 우승자인 AlexNet의 Hyper Parameter를 조금 수정한 동일한 구조의 모델이기에 소개하지 않겠습니다.)
1. AlexNet

AlexNet은 2012년에 등장해 Imagenet classification에서 좋은 성적을 거뒀습니다. 처음으로 CNN Architecture을 사용한 모델이었고 AlexNet의 구조는 위와 같습니다. Convolution layer, Max Pooling Layer, Normaliztion이 2차례 반복되고 3개의 Convolution Layer와 1번의 Max Pooling을 거친 후 Fully Connected Layer가 3번 나오는 구조입니다.
ImageNet의 input image 크기는 227x227x3의 크기이고 첫번째 층에서 11x11의 필터로 4 strides로 Convolution을 진행합니다. 따라서 필터를 거치고 난 후의 출력 크기는 55x55크기가 됩니다.( (227-11)/4+1 = 55 ) 필터의 크기와 stride를 설정하는 것은 출력 값이 정수로 나오도록 잘 조정해줘야 하기때문에 이 식을 알고 계시는 것이 좋습니다. 그리고 이 첫번째 필터에서 파라미터의 갯수는 3x11x11x96이 됩니다. 96개의 필터에 각각 11x11 사이즈로 3차원의 input이 있기 때문이죠.

AlexNet의 모든 층의 output 크기와 각 층에서 필터 사이즈를 정리하면 위와 같습니다. 마지막 FC8(Fully Connected)는 classification을 위한 softmax 층입니다.

AlexNet의 hyper parameter는 위와 같습니다.
또한 AlexNet의 특이한 점은 첫번째 사진을 보시면 몇개의 층들이 두개로 나누어져 있다는 점입니다. 이는 2012년 당시 사용한 GPU가 GTX 580이라서 3GB 메모리 크기를 가졌기 때문에 모든 네트워크를 하나의 GPU에서 훈련시킬 수 없었습니다. 따라서 2개의 GPU를 이용해 네트워크를 둘로 나누어 훈련시켰습니다. 단, 3번째 Convolution Layer와 3개의 Fully Connected Layer에서는 2개의 GPU가 서로 소통하며 네트워크를 구성합니다.
2. VGG Net
앞에서 알아본 AlexNet은 8개의 층을 가지고 있었습니다. 2014년에 등장한 GoogLeNet과 VGG Net의 이전과 다른 큰 차이점은 각각 22개, 19개의 층을 가진 더 깊은 모델이라는 점입니다. 먼저 VGG Net에 대해 알아보겠습니다.

앞서 말했듯이, VGG Net은 AlexNet보다 더 깊은 구조의 층을 가지고 있음을 확인할 수 있습니다. AlexNet과 비교해 보았을때 Convolution Layer의 필터는 3x3 크기와 stride 1, padding 1을 사용했고, 2x2 Maxpooling 을 strides 2로 사용하는 등 더 작은 크기의 필터를 사용했습니다.
이렇게 더 작은 필터를 사용한 이유는 무엇일까요? 이는 3x3 필터 2개를 사용하면 5x5 필터 하나를 사용한 것과 같은 효과를 볼 수 있기 때문입니다. 여기에 3x3 필터를 하나 더 추가한다면 7x7 필터 하나와 같은 효과를 보입니다. 또한, 두 경우가 같은 성능을 보이지만 parameter 개수는 3x3 필터 2개를 사용한 것이 더 적습니다.( 3x(3x3xCxC) < 7x7xCxC, C는 채널 수) 따라서 더 작은 필터를 여러겹 쌓는 것이 같은 성능을 보이면서 연산시간을 줄일 수 있기 때문에 더 좋다고 할 수 있습니다.

VGG Net의 각 층에 대한 filter size와 parameter수, memory 용량은 위와 같습니다. 이미지당 96MB의 메모리와 138M개의 파라미터를 가지고 있습니다. 이는 순전파 때의 경우만 말한 것이고 역전파를 할 때에는 더 큰 메모리가 필요합니다. 따라서 굉장히 큰 메모리를 필요로 한다고 할 수 있습니다. 한가지 알아둘 점은 초기의 Convolution Layer가 많은 메모리를 차지하고 마지막 부분의 Fully Connected Layer가 많은 Parameter를 차지한다는 점입니다. 나중에 나올 모델들은 Fully Connected Layer의 parameter를 줄이기 위해 노력합니다.

VGG Net의 상세한 내용은 위와 같습니다. 기본적으로 2012년의 AlexNet과 유사한 구조를 가지고 있고, Normalization을 하지 않았습니다.
3. GoogLeNet

GoogLeNet의 특징적인 점은 네트워크는 더 깊어졌지만 연산 효율은 증가했다는 점입니다. 22개의 층을 가지고 있지만 Fully Connected Layer를 없애서 5M개의 parameter를 가지고 있습니다. 이는 AlexNet의 parameter 갯수보다 적습니다.

또한 GoogLeNet은 Inception Module이란 것을 사용했습니다. 위의 사진에서 각 층에서 여러개의 화살표로 뻗어나가서 하나로 합쳐지는 모양을 확인하실 수 있는데 이것이 Inception Module입니다. Inception Module이란 input으로 들어온 데이터를 하나의 층에서 여러 필터 사이즈로 Convolution을 병렬적으로 행합니다. 이렇게 해서 나온 output들을 모두 엮어서 다음 층으로 전달합니다.
하지만 이런 Inception Module에는 문제가 있습니다. 위의 사진과 같은 경우에 Input의 크기는 28x28x256이지만 output의 크기가 28x28x672가 됩니다. 이에 따라 연산량을 계산해보면 1x1 Convolution에서는 28x28x128x1x1x256, 3x3 Convolution에서는 28x28x192x3x3x256, 5x5 Convolution에서는 28x28x96x5x5x256으로 총 연산량이 845M에 달합니다.

그래서 GoogLeNet은 이 Inception Module을 발전시켜 사용했습니다. Convolution을 실행하기 전에 1x1 Convolution을 통해 input의 차원을 줄여주는 것이죠. 이를 통해 연산량을 줄일 수 있었습니다. 이렇게 차원을 줄여주는 것을 bottleneck layer라고 부릅니다. 위의 예시에 bottleneck을 적용했을 경우엔 358M의 연산이 필요하고 이는 bottleneck이 없을 때와 비교하면 굉장히 큰 차이입니다.
또한 특이하게도 맨 마지막 부분 뿐만아니라 중간에 2부분에서 Classification의 결과물을 확인할 수 있습니다.

GoogLeNet의 정보는 위와 같습니다. 총 22개의 층이 있고 효율적인 Inception Module을 사용했으며 Fully Connected Layer를 사용하지 않았습니다.
4. ResNet
ResNet 구조는 이전과 비교해서 매우 깊은 152개 층의 네트워크로 구성되어 있습니다. 또한 2015년에 대부분의 대회에서 수상할 정도로 굉장히 뛰어난 성적을 보였습니다. ResNet의 아이디어는 평범한 Convolution Layer를 아주 깊게 쌓는다면 어떻게 될까에서 시작되었습니다.

하지만 이렇게 층을 깊게 쌓기만 하는 것은 좋지 못했습니다. 위의 그래프에서 56개의 층을 쌓아 올린 모델이 20개의 층을 가진 모델보다 안 좋은 성적을 보이는 것을 확인 할수 있습니다. 56-layer를 가진 모델이 training에서도 좋지 않은 성적을 보입니다. 여기서 알 수 있는 사실은 더 깊은 모델이 overfitting 되지 않는 다는 점이었습니다. 그래서 이제 사람들은 깊은 네트워크의 성적이 좋지 않은 것이 최적화가 되지 않았기 때문이라 생각하고 이것을 어떻게 최적화시킬 것인지 고민하게 됩니다.
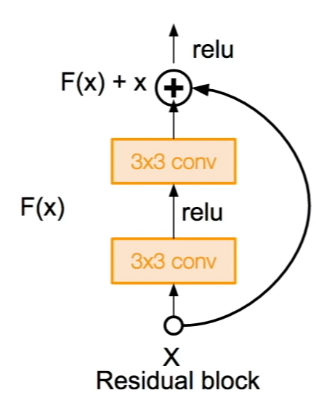
그래서 고안해 낸것이 이 Residual Block입니다. 입력으로 들어온 값들과 Convolution을 거친 값들을 더해서 다음 층으로 전달합니다. 이렇게 입력으로 들어온 값을 바로 출력부로 연결하는 것을 Skip Mechanism이라고 합니다. 또한 기존 네트워크와는 다르게 ResNet에서는 F(x)가 0이 되는 방향으로 학습을 진행합니다. 이렇게 생성된 여러개의 Residual Block이 ResNet을 구성합니다.

그렇게 생성된 ResNet의 구조는 위와 같습니다. 반복적으로 Convolution Layer의 필터 개수를 2배로 증가시키고 stride 2로 downsampling을 합니다. 그리고 Classification을 위한 1000 Fully Connected Layer만 사용합니다. 또한 네트워크가 깊어짐에 따라서 GoogLeNet에서 사용했던 Bottleneck을 적용해 효율성을 증가시켰습니다.

ResNet의 세부사항은 위와 같습니다.
5. Compare Complexity

위의 그래프는 각 모델들의 정확성과 메모리 사용량, 연산량을 표시한 것입니다. VGG는 상당히 많은 연산량과 메모리를 필요로 함을 알수 있습니다. 가장 높은 정확도를 보이는 Inception-v4는 Inception과 ResNet을 합친 것입니다.
CS231n 9장 강의에선 추가적으로 간단하게 다른 구조들을 소개합니다. 이 글에선 그 모든 내용을 다루지 않을 예정입니다. 혹시 궁금하신 분들은 아래 주소에서 내용을 확인하시면 됩니다. 감사합니다.
https://www.youtube.com/watch?v=DAOcjicFr1Y&list=PL3FW7Lu3i5JvHM8ljYj-zLfQRF3EO8sYv&index=10&t=0s
'Machine Learning' 카테고리의 다른 글
| [CS231n] 8. Deep Learning Software(2) - Frameworks (0) | 2020.01.16 |
|---|---|
| [CS231n] 8. Deep Learning Software(1) - CPU vs GPU (0) | 2020.01.15 |
| [CS231n] 10. Recurrent Neural Networks (0) | 2020.01.11 |
| [Deep Learning from Scratch] 7장. 합성곱 신경망 (0) | 2020.01.09 |
| [Deep Learning from Scratch] 8. 딥러닝 (0) | 2020.01.09 |

