저번 시간에는 CNN 구조에 대해서 배웠습니다.
오늘은 Recurrent Neural Network(RNN) 에 대해서 배워보도록 하겠습니다.
Recurrent Neural Networks
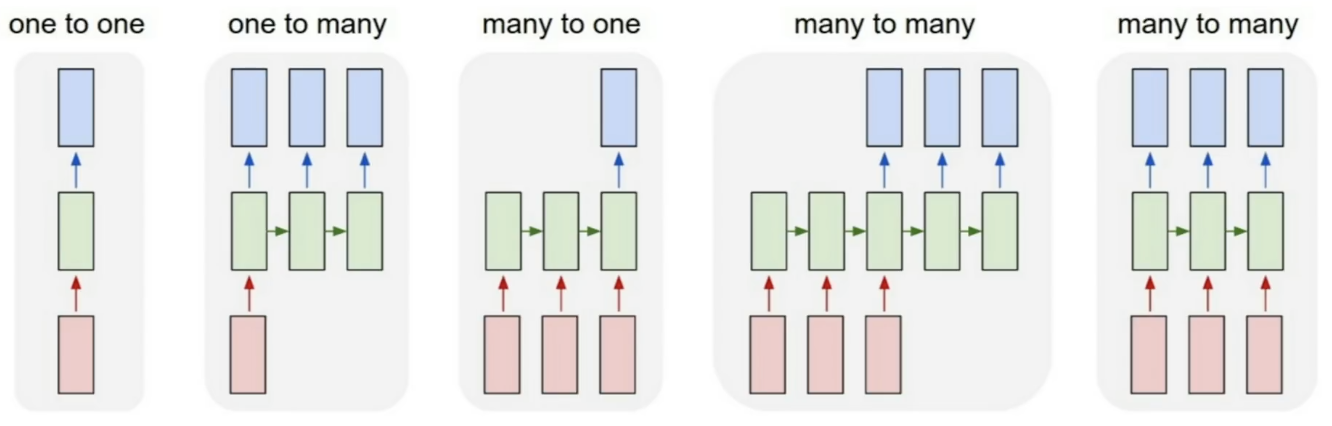
RNN은 위처럼 생긴 모델들을 의미합니다. 모델의 아웃풋을 통해 다시 그 모델을 반복적으로 학습하게 되는 구조를 띄고 있습니다.
one-to-one은 하나의 인풋에 대해서 하나의 아웃풋이 나오는 모델이며 Vanilla Neural Networks라고 부릅니다. one-to-many는 하나의 인풋에 대해 여러개의 아웃풋이 나오는 모델로 보통 Image Captioning을 할 때 사용됩니다. 하나의 이미지에 대해서 여러개의 단어들을 뽑아내어 캡션을 달아줍니다. many-to-one은 여러개의 인풋에 대해 하나의 아웃풋만 나옵니다. 이는 보통 감정구별할 때 많이 쓰입니다. 대표적인 예시로 영화를 본 후기를 보고 긍정적인지 부정적인지 알려주는 것입니다. 그 다음은 many-to-many입니다. 여러개의 인풋이 들어가 여러개의 아웃풋이 들어가는데 이는 2가지로 나뉩니다. 인풋이 들어갔을 때 바로 아웃풋이 나오는지에 대한 유무로 나뉘게 됩니다. 바로 나오지 않는다면 기계번역할 때, 바로 나온다면 비디오에서 프레임 단위로 classification할 때를 대표적인 예시로 들 수 있습니다.
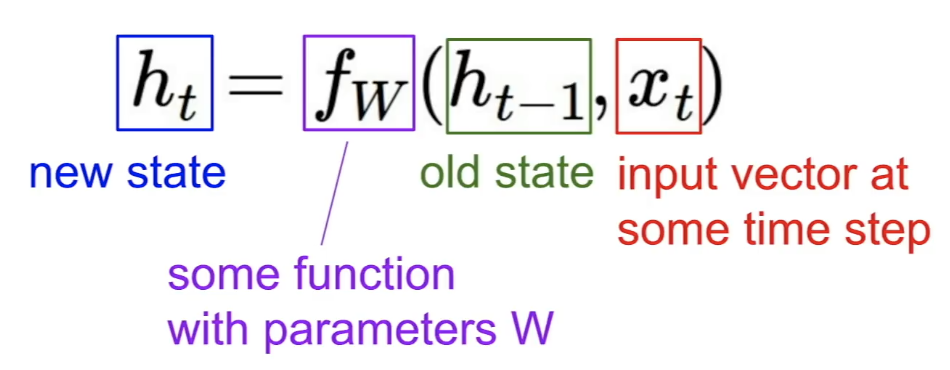
old state에서 나온 output과 현재 time step에서의 input vector를 모델에 넣어서 나온 output이 그 다음 state가 되게 됩니다.

실제로는 다음과 같은 방식으로 학습이 됩니다. 위 예시는 many-to-many 경우인데요, 모든 함수 f가 같은 가중치를 공유하게 됩니다. 같은 가중치를 반복적으로 계속 학습하게 되는 것이죠. loss는 여러개의 아웃풋에 대해서 각각의 loss를 구하고 이들을 전부 반영하여 총 loss를 구하게 됩니다.

Sequence to Sequence의 경우에는 many-to-many에 포함되지만 정확히 구조를 따져보면 input sequence들을 encoding해주는 many-to-one과 input vector로부터 output sequence를 decoding하는 one-to-many의 합으로 이루어져 있습니다.

RNN의 예시로 Character-level Language Model을 보도록 하겠습니다. 이 모델은 인풋으로 문자 하나하나가 들어가게 됩니다. 만약 hello라는 문자열을 학습하고 싶다면 hell이 들어가서 ello가 나오도록 학습하게 됩니다. output이 나오면 softmax로 문자를 예측합니다.

그러나 이 방법은 backpropagation을 할 때 시간을 전혀 고려할 수 없게 됩니다. 그래서 사람들은 새로운 방법을 생각해냅니다. 더 작은 단위로 나눠서 loss를 합쳐 계산하는 방법입니다.
이 Character-level Language Model로 학습하면 매번 다음 글자를 예측해냄으로서 C 코드, 셰익스피어의 글, 수학책 등등 여러가지 것들을 생성해낼 수 있습니다. 물론 학습할 때 원하는 스타일에 맞는 글을 학습시켜야 원하는 텍스트를 만들어낼 수 있을 것입니다.
이제 RNN을 사용하는 여러가지 방법에 대해 조금 더 자세히 알아보겠습니다.
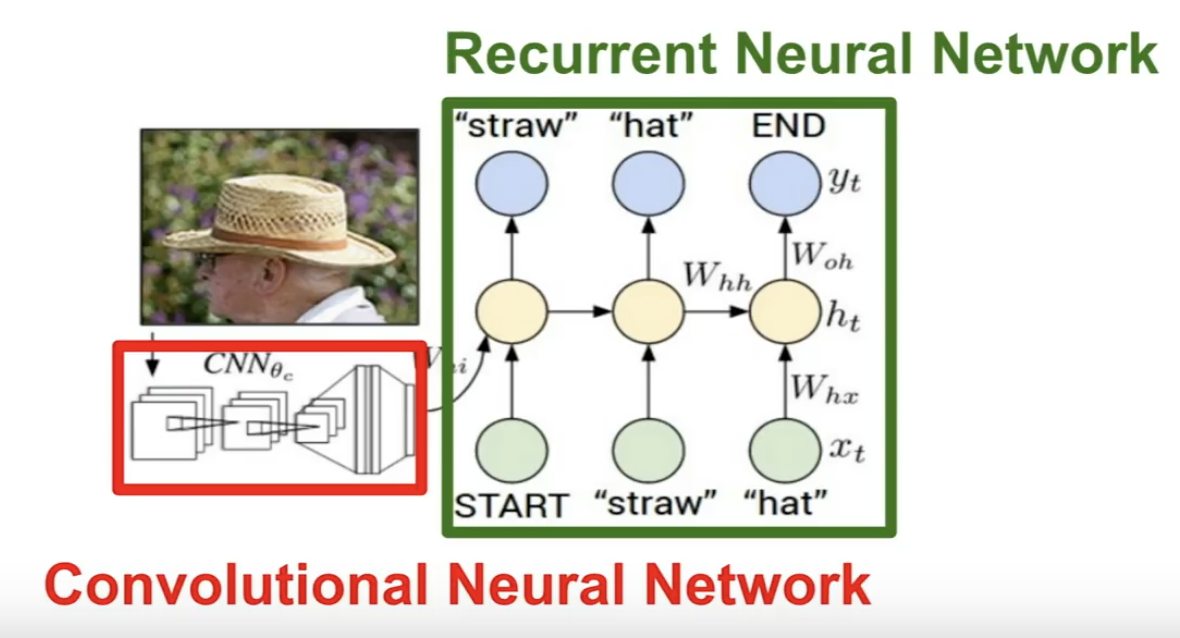
Image Captioning 같은 경우에 다음과 같은 Neural Network로 이루어져 있습니다. CNN이 끝나고 그 결과가 RNN의 첫번째 state로 들어가게 되는것입니다. 만약 RNN을 학습하다가 데이터셋에 있는 문장이 끝나게 되면 토큰을 사용해 종료됨을 알려줍니다. 이렇게 학습을 하면 실제로 테스트할 때도 문장을 만들다가 끝이 나면 토큰을 반환해주어 끝을 알려줍니다.
다음은 Image Captioning의 예시입니다.

다음으로 Visual Question Answering에 대해서 알아보겠습니다.

오른쪽 그림에서 질문을 받고 그에 대한 답변을 정확하게 해주는 모습을 볼 수 있습니다. 여기서는 CNN을 통해 이미지를 인코딩한 후 질문과 이 이미지를 인코딩한 값을 LSTM(RNN과 비슷한 모델입니다. 뒤에 다시 나옵니다.)에 넣고 다음 셀로 연결할 때 convolutional feature map과 attention term을 같이 반영합니다. 질문을 보고 어디를 집중적으로 볼지를 정하게 되는 것입니다. 그걸 정하고 나면 최종적으로 집중적으로 보는 부분을 CNN을 통해 인코딩한 값과 LSTM의 아웃풋을 토대로 답변을 생성합니다.
Multilayer RNN이라는 것도 있습니다. hidden layer를 하나만 쓰는 것이 아닌 여러개를 쓰는 방법입니다. 구조는 다음과 같습니다.

이제 RNN이 학습할 때 어떤 일이 일어나는지 알아보겠습니다.

h_t가 다음과 같은 식으로 이루어지고 여기서 backward propagation이 일어날 때 h_t 가 차례대로 오차를 역전파하여. h_t-1을 변화시키고 모델 안의 가중치 또한 변화시킵니다.
그러나 이 RNN은 큰 문제가 있습니다. exploding or vanishing gradients 문제가 발생합니다. gradients가 발산하거나 수렴하여 학습이 제대로 안되는 경우가 생기고 앞에 나온 단어에서 뒤에 나온 단어에 영향을 줄 때 이런 경우를 전혀 학습할 수 없게 됩니다. 이를 해결해주는 모델을 알아보겠습니다.
1997년에 나온 Long Short Term Memory(LSTM)을 배워보겠습니다.

RNN과 다르게 f,i,o,g 4개의 값이 사용됩니다. f는 forget gate로 이전 셀의 값을 얼마나 기억할지를 정하는 변수이고, i는 input gate로 현재 셀의 값을 얼마나 반영할지를 정하는 변수입니다. o는 output gate로 outside로 현재 셀 안에서의 값을 얼마나 보여줄지를 정해주고, g는 gate gate로 이 셀에 얼마나 학습시킬지를 정하는 변수입니다.
LSTM은 forget gate의 존재로 인해 exploding or vanishing gradients 문제를 쉽게 해결할 수 있습니다.

저번 시간에 배운 ResNet과 비슷한 개념이라고 보면 이해가 쉬워질 것 같습니다.
오늘 배운 내용들을 요약하면 다음과 같습니다.
- RNN은 모델 디자인할 때 유연합니다
- Vanilla RNN은 간단하지만 잘 작동하지 않습니다
- LSTM 과 GRU를 많이 씁니다.(그들의 복잡한 상호작용이 gradient flow를 좋게 만들어줍니다.)
- RNN에서 backward propagation을 할 때 gradients가 발산하거나 수렴합니다. 발산하는 경우에는 gradient clipping으로 컨트롤할 수 있고 수렴할 때는 LSTM을 사용하여 컨트롤할 수 있습니다.
Gradient clipping: gradient의 최대 크기를 제한하고 이를 넘으면 크기를 재조정하여 너무 크게 벗어나지 않도록 함
이상으로 10장 Recurrent Neural Networks를 마칩니다.
'Machine Learning' 카테고리의 다른 글
| [CS231n] 8. Deep Learning Software(1) - CPU vs GPU (0) | 2020.01.15 |
|---|---|
| [CS231n] 9. CNN Architecture (0) | 2020.01.15 |
| [Deep Learning from Scratch] 7장. 합성곱 신경망 (0) | 2020.01.09 |
| [Deep Learning from Scratch] 8. 딥러닝 (0) | 2020.01.09 |
| [Deep Learning from Scratch] 6장. 학습 관련 기술들 (0) | 2020.01.08 |


