Ensemble 에 대해 공부하셨다면 Soft Voting 과 Hard Voting에 대해서 알고 있으시겠지만, 대부분 개념은 대충 넘기고 모듈을 사용하기 때문에 정확한 개념을 헷갈리는 경우가 있습니다. 저도 자료들을 찾아보면서 한동안 혼란을 겪었는데, 가장 큰 이유는 적지 않은 사이트들이 Soft Voting 과 Weighted Voting을 섞어 쓰기 때문이었습니다. 한번 확실하게 알아 봅시다. 참고로 본 포스트의 모든 내용은 Classification 문제에 대한 것이라고 생각하시면 됩니다.
voting이 뭔지 잘 모르시겠으면 이 포스트 를 참고해 주세요
Hard Voting
Hard Voting은 Majority Voting이라고도 하며, 각각의 모델들이 은 각각의 모델들이 결과를 예측하면 단순하게 가장 많은 표를 얻은 결과를 선택하는 것입니다. 정말 easy 하죠? Soft Voting과의 차이를 확실하게 하기 위해 각 모델이 class별 probability도 예측할 수 있는 예시를 보겠습니다.

Soft Voting
Soft Voting, 다른말로 Probability Voting도 매우 간단합니다. 각 class별로 모델들이 예측한 probability를 합산해서 가장 높은 class를 선택하면 됩니다.
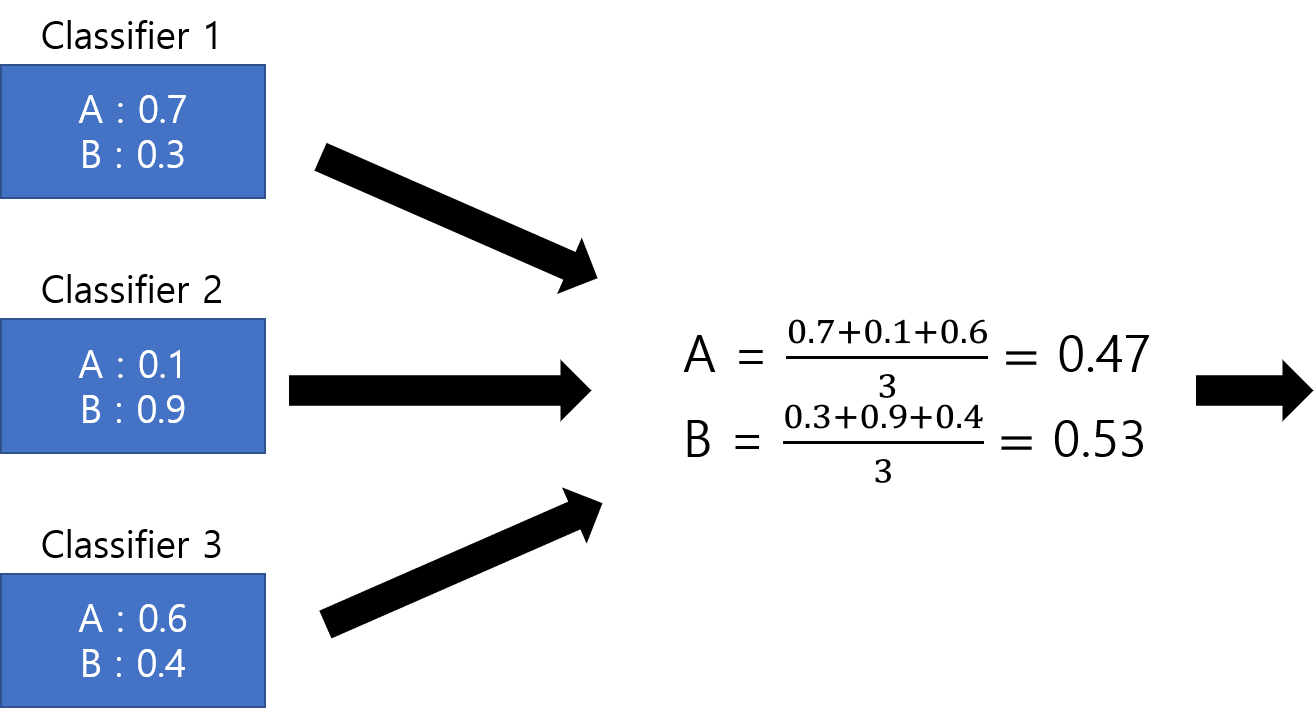
Weighted Voting
Weighted Voting은 각각의 모델별로 가중치를 주는 것입니다. 가중치를 주는 방법에는 여러가지가 있겠지만, 단순하게 생각했을 때는 train dataset에 대해서 각 모델들이 내는 score에 비례해서 주면 되겠죠? Soft Voting과 Hard Voting은 공존 불가능한 두 방법이고, Weighted Voting은 옵션이라고 보시면 됩니다. 이는 scikit learn 을 많이 사용해 보셨다면 당연히 아실텐데, Voting Classifier에서 voting은 ‘soft’ 와 ‘hard’ 중에 선택할 수 있고 (default = ‘hard’), weights는 옵션을 줄 수도 있고 안 줄 수도 있습니다.

이렇게 보면 정말 쉽고 확실하지만, Soft Voting과 Weighted Voting을 헷갈리는 이유는 말로 풀어 썼을 때 굉장히 비슷하기 때문입니다. 두 방법 모두 더 ‘확실한’ 모델에 대해서 더 큰 가중치를 주는 것이기 때문이죠. Soft Voting도 probability 계산을 못하는 관점에서 생각해보면 A가 0.9라고 한 모델이 A가 0.6이라고 한 모델보다 ‘확실’하기 때문입니다. 하지만 Soft Voting은 각 모델이 자기가 얼마나 확실한지를 반영하는 것이고, Weighted Voting은 전체 모델들 중에 얼마나 확실한지를... 말로 설명하려니 어렵네요. 이 포스트를 읽으셨고 확실히 구분이 된다면 이 문단은 무시하셔도 됩니다.
Decision Tree Classifier의 Probability 계산
그런데 제가 제대로 알고 있는 유일한 모델인 Decision Tree는 답을 확률로 알려주는 것이 아니니 Soft Voting이 불가능할까요? 놀랍게도 scikit learn에서 제공하는 DecisionTreeClassifier에는 각 class의 확률을 계산해주는 predict_prob 함수가 있습니다. 확률을 계산하는 방법은 단순하게 train dataset(의 일부) 를 Decision Tree에 넣어보고 각 leaf로 나오는 값들 중 정확한 값인 비율을 계산합니다.
그런데 이를 조사하며 몰랐던 것을 하나 알게되었는데, scikit learn의 DecisionTreeClassifier는 max_depth를 임의로 정해주지 않으면 자동으로 모든 leaf가 pure해질때까지 나눕니다. 그말인 즉슨, 모든 leaf가 확실한 leaf이고, 확률은 모두 해당 클래스에 대해서만 1이라는 것이죠.
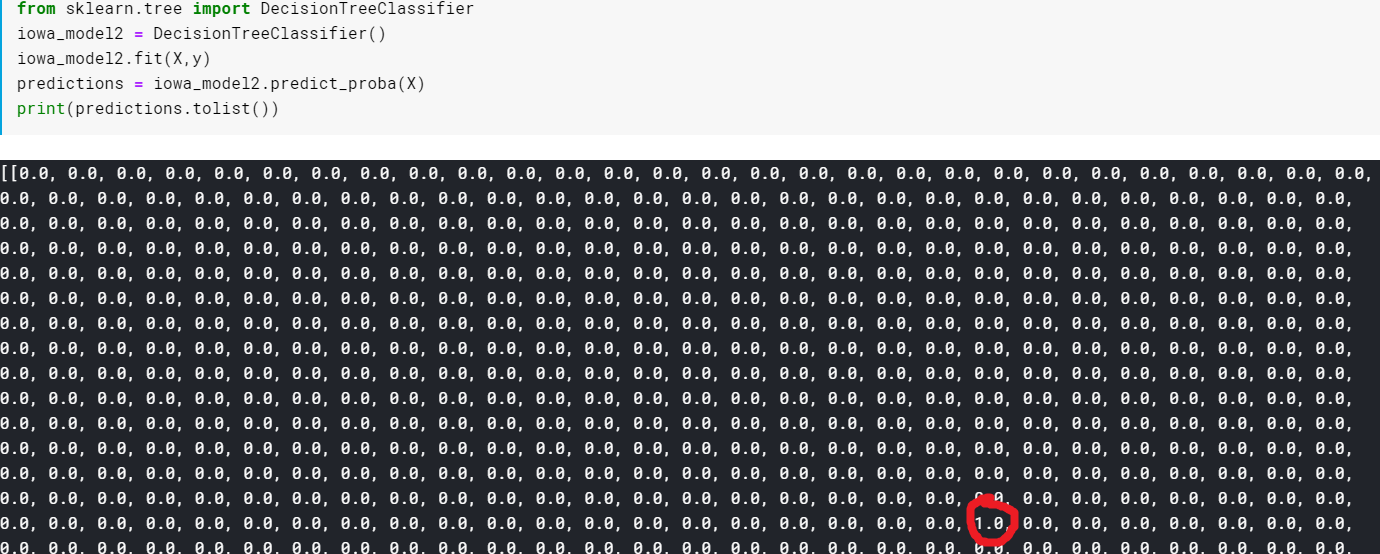
따라서 저희는 Soft Voting을 하려면 각 모델들을 잘 설정해야 하는 이유를 한가지 생각할 수 있습니다. 모델들이 overfitting이 되어서 train dataset에 대해서 너무 정확한 결과를 내게 되면, probability 가 모두 1에 가깝게 되어서 사실상 Soft Voting을 하는 이유가 없어집니다. ( 물론 Decision Tree 의 depth가 너무 깊어지는 것은 Overfitting과는 좀 다릅니다. )
Soft Voting v.s Hard Voting
모든 모델이 probability 계산이 된다면 단순하게 Soft Voting, Hard Voting두개만 놓고 고르라고 했을 때 Soft Voting을 고르지 않을 이유는 없습니다. 하지만 더 다양한 방법들을 생각해보면 Hard Voting을 사용할 일이 없는 것은 아닙니다. 쉽게 생각할 수 있는 한가지 예는 다음과 같습니다.
어떤 class에 대한 probability 가 일정 값보다 큰 모델들만 따로 모아서 이들에 대해서만 Hard Voting 을 진행한다.
나름 합리적인 Voting 입니다.
이처럼 단순히 Hard Voting, Soft Voting 만 사용해야 하는 것은 아닙니다. 여러분도 한번 그럴듯한 Voting 알고리즘을 생각하고 구현해 보시면 좋겠죠?
'Machine Learning' 카테고리의 다른 글
| [Deep Learning from Scratch] 2장. 퍼셉트론 (0) | 2020.01.08 |
|---|---|
| 딥러닝을 통한 Image Segmentation 입문!! (1) | 2019.12.02 |
| 머신 러닝 입문자를 위한 설명 - 교차 검증(K-Fold Cross Validation) (0) | 2019.10.28 |
| 컴퓨터의 시각 인식에 대해 알아보자 (0) | 2019.10.28 |
| Boosting과 친해져보자! (0) | 2019.10.27 |



