
The Beginner's Guide to Computer Vision
원문 링크 : https://www.kaggle.com/sandeeppat/the-beginner-s-guide-to-computer-vision/notebook
Intro
안녕하세요 여러분!
이 글은 컴퓨터의 시각 인식과 특히 컴퓨터가 어떻게 이미지를 처리하는지에 대해서 처음 알아보는 분들께 가이드가 되고자 만들어진 커널입니다.
저희가 이번 커널에서 다룰 내용은 아래와 같습니다 -
Section A
- 이미지가 컴퓨터에 어떻게 저장되며, 왜 그렇게 저장되는가?
- 이미지를 어떻게 읽어오고, 그 속성을 어떻게 확인하는가?
- 훈련 목적의 요구사항에 맞게 이미지의 사이즈를 재설정하는 방법은 무엇인가?
Section B
- 커널 transformation과 multiplication 의 기초
- Kernel, Filter, Padding등의 용어에 대해 알아봅시다
- Convolution이 무엇인지, 그리고 어디서 동작하는지를 알아봅시다
- 이미지의 채널(channel) 개수가 학습 목적에 따라 어떻게 바뀔 수 있는지 알아봅시다
Section C
- 가장 기초적인 컴퓨터 시각 인식 모델 구조를 만드는 법을 배워봅시다.
- 그 다음에는 분류 문제에 대해 모델을 학습시키는 법에 대해 알아봅시다
Section A

IMAGES
우리가 이미지를 보는것과 컴퓨터가 이미지를 저장소에 저장하는 방식은 매우 다릅니다.
이미지는 기본적으로 수많은 픽셀의 집합인데, 픽셀은 우리가 보는 이미지를 구성하는 가장 작은 단위를 말합니다.
주요 색깔 - 빨강(제가 가장 좋아하는 색깔), 초록, 파랑

이러한 이미지들을 저장하는 가장 보편적인 방법은 숫자의 배열 의 형태로 저장하는 것인데, 배열 안의 숫자들은 세가지 주요 색깔들 (RGB)의 정도를 나타냅니다.
이 이미지들은 RGB 형태로 주로 저장되는데, 세가지 색깔의 비율을 조정함을 통해서 모든 색깔을 만들어낼 수 있기 때문입니다.
간단히 말해, ** RGB 각각의 색깔마다 이차원 배열이 존재하게 됩니다. **
PS: 이미지를 저장하는 여러 다른 방법들도 있는데, 이미지 처리에 대해 깊숙히 들어가면 이를 만나게 됩니다.
Reading an Image
우리는 이미지를 읽어오기 위해서 OpenCV library를 사용하게 되며, 이미지에 약간의 조작을 가해봅시다.

이미지의 형태를 관찰해봅시다.

위에서 보다시피 우리가 가지고 있는 이미지는 (500, 500, 3) 의 형태를 가지고 있는데, (500, 500) 형태의 2차원 배열이 세개 있다는 것을 의미합니다 (각각 빨강, 초록, 파랑)
이번에는 이미지 자체를 살펴봅시다.

우리는 OpenCV의 resize() 함수를 이용하여 우리가 원하는대로 이미지를 resize 할 수 있습니다.
이미지의 사이즈가 클수록, 이미지가 세분화되는 정도가 커집니다. 따라서, 이미지를 처리하는데 더욱 많은 컴퓨터 자원이 사용되게 되지요.
따라서, 자원의 한계때문에, 보통 우리는 이미지의 사이즈를 (300, 300) 이하로 유지하며, 그보다 큰 이미지들은 모델에 맞게 resize 하여 사용하게 됩니다.

위에 보이는 것이 아까의 같은 이미지를 낮은 사이즈로 재조정한 것으로, 사진에서 보다시피 많은 정보&세부적 요소의 손실 이 일어난 것을 확인할 수 있습니다.
잠시 지금까지 우리가 다룬 것을 복기해보자면..
- 이미지가 컴퓨터에 어떻게 저장되며, 왜 그렇게 저장되는가?
- 이미지를 어떻게 읽어오며 어떻게 사이즈를 확인하고, 어떻게 이미지를 보는가?
- 훈련 목적에 맞게 이미지의 사이즈를 어떻게 바꾸는가?
이제, 우리는 분류 문제들을 풀고, 이미지를 대상으로 훈련할 매우 기초적인 Convolution 구조를 만들어보도록 하겠습니다.
Section B
CNN Basics
모델을 만들고 이미지를 분류하기 전에, CNN 모델이 어떻게 동작하는지 잠시 알아보도록 합시다.
우리가 위에서 말했던 것처럼, 우리가 앞으로 channel(채널) 이라고 부를 이차원 배열들이 있습니다.
이제, 모든 채널들은 각각 또다른 조금 더 작은 이차원 배열인 kernel(커널) 이라는 것을 이용한 변화를 거치게 됩니다.
변화의 과정은 다음과 같습니다 -
- 기존의 우리가 가진 배열과 kernel 배열이 곱해져 하나의 스칼라 값을 생성합니다.
- 커널 배열은 우리가 가진 배열을 상하좌우로 쭉 순회하며 계속해서 또다른 스칼라 값을 생성해냅니다.
- 커널 배열이 순회를 마칠때까지 반복한 후 생성된 스칼라 값을 이용해서 새로운 배열을 생성해냅니다.
위 과정을 시각적으로 보자면 아래와 같습니다 -

위 과정을 더 나은 이해를 위해 완전히 애니메이션으로 만들어보자면 아래와 같습니다.
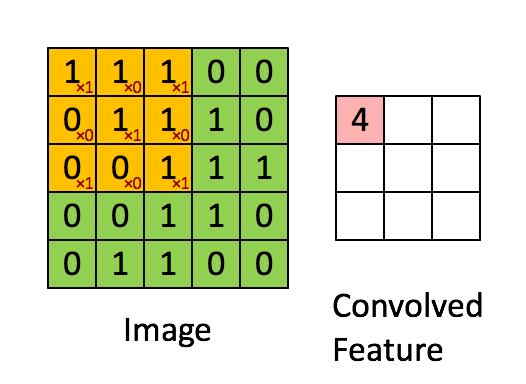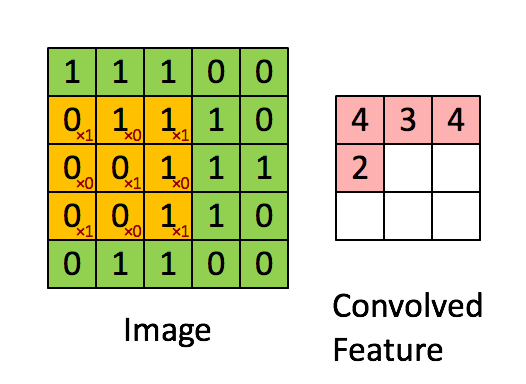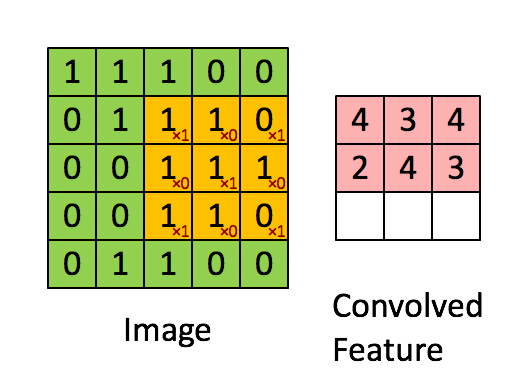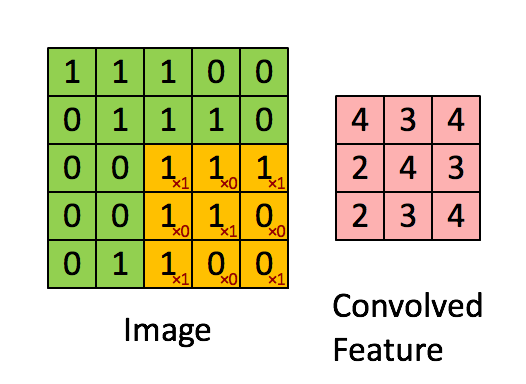
'Padding' 개념에 대한 이해
우리가 여기서 관찰할 수 있는 가장 명확한 사실은 바로 결과로 나온 배열의 사이즈가 우리가 기존에 가지고 있던 배열보다 작다 는 것입니다.
우리는 (5,5) 사이즈의 배열로 시작해서 위의 과정을 거치자 (3,3) 사이즈의 배열을 가지게 되었습니다.
이는 정보의 손실을 의미하며, 여기서 우리의 원래 배열의 사이즈를 보존하기 위해서 "Padding(패딩)" 이라는 개념이 등장합니다.
패딩은 기존의 배열의 각 모서리에 추가적인 칸을 더함으로써 kernel 작업이 완료된 후에도 같은 사이즈의 배열이 결과로 반환되도록 합니다.
패딩 작용을 시각적으로 보자면 아래와 같습니다.

따라서, 우리는 이제 입력으로 들어왔던 배열과 같은 사이즈의 배열을 가지게 됩니다.
위 과정을 다중 채널에 적용하기
다음으로 가장 중요한 것으로 넘어가자면, 지금까지 우리는 하나의 특정한 채널에 대해서 배열 곱 과정 (kernel operation) 을 수행해 결과 채널을 생성했습니다.
이제, 우리가 알듯이 이미지는 하나 이상의 채널로 보통 구성되어 있습니다. (단, greyscale 이미지는 흑백 상태이므로 한개의 채널만을 가지고 있습니다)
따라서, 우리는 이제 우리의 지식을 세개 혹은 그 이상의 차원으로 확장할 필요가 있습니다.
Filter에 대해 알아보기
여기서 "Filter(필터)" 라고 알려진 'kernel'과 함께 많이 쓰이는 용어가 등장합니다.
정확하게 알아두자면, 여러개의 "커널"이 합쳐진 것을 우리는 "필터" 라고 부릅니다.
즉, 3개의 채널을 가진 배열을 처리한다고 할때, 우리는 각각 하나씩 해서 세개의 커널이 필요할 것입니다.
그리고, 이 세개의 커널이 모여 하나의 "필터" 를 만들어냅니다.
전체 과정을 한번 살펴보고, 세부적인 과정을 살펴봅시다.
Step 1
이미지의 세가지 서로 다른 채널에 각각 세개의 커널이 작용해 아래서 보다시피 세개의 결과 배열을 내놓습니다.

Step 2
위에서 생성된 것들이 함께 모여 하나의 채널을 생성합니다.
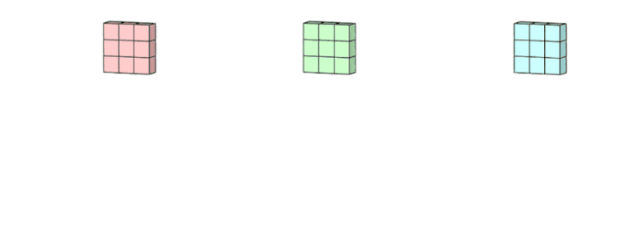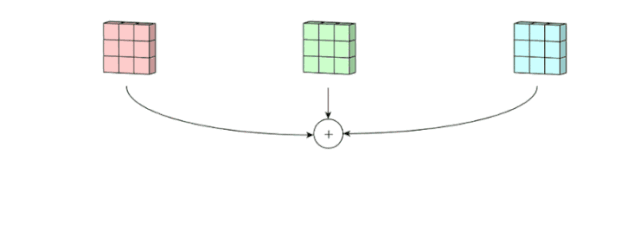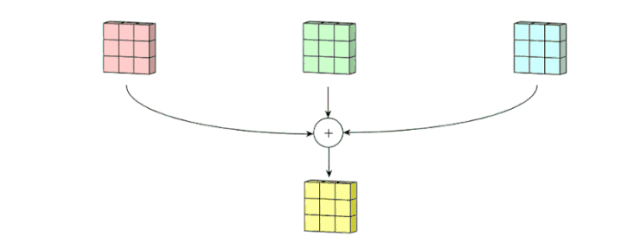
따라서, 보다시피 하나의 필터는 하나의 채널을 결과적으로 생산합니다.
즉, 우리가 만약 x개의 결과 채널을 원한다면, 우리가 해야하는 것은 이미지를 받아서 여러 커널들로 이루어진 x개의 필터를 만드는 것입니다.
우리의 첫 모델을 만들기에 앞서, 우리는 이미지를 102개 종류로 분류하려고 하기 때문에, 우리의 모델이 102개의 값을 주면 이를 SoftMax 계층의 입력으로 넣어주어 이미지가 각각의 종류에 속할 확률을 결과로 받을 것입니다.
더 나아가기 전에, 우리가 이번 섹션에서 알아본 정보들을 복기해봅시다
- 커널 변화와 곱(multiplication) 의 기초
- Kernel(커널), Filter(필터), Padding(패딩)과 같은 용어들
- Convolution이 무엇이고, 실제로 어떻게 동작하는가?
- 이미지의 다수의 채널들이 어떻게 처리되며 변화되어가는가?
Section C
가장 기초적인 모델을 만들어봅시다
FastAI를 이용해서 정말 간단한 모델 만들기

아래 코드의 인자들을 각각 살펴보자면 다음과 같습니다 -
- 입력 채널의 수
- 결과 채널의 수
- 커널의 사이즈 (보통 3*3 이나 5*5 를 사용합니다)
- Stride (아직 이것에 대해 배우지 않았으므로, 그냥 그렇구나 하고 넘어가세요)
- 패딩 (Padding)

모델을 한번 살펴봅시다

후략... (실습과정이므로 생략합니다)
마치며..
지금까지 CNN의 기초와, 가장 기초적인 이미지 분류를 위한 CNN 모델을 만들어보았습니다.
이 기초 튜토리얼을 마치셨다면, MNIST 데이터셋 칠린지가 더 나아가는 데 좋은 중간점이 될 것입니다.
혹시 이미지 분류와 기술들에 대해 더 자세히 알고 싶으시다면 아래 커널을 참조하세요!
https://www.kaggle.com/sandeeppat/ship-classification-top-3-5-kernel
'Machine Learning' 카테고리의 다른 글
| Soft Voting 과 Hard Voting (0) | 2019.10.29 |
|---|---|
| 머신 러닝 입문자를 위한 설명 - 교차 검증(K-Fold Cross Validation) (0) | 2019.10.28 |
| Boosting과 친해져보자! (0) | 2019.10.27 |
| 중학생도 쉽게 이해하는 Gaussian Naive Bayes Classifier (2) | 2019.10.26 |
| Ensemble의 기법 (1) | 2019.10.23 |



